I have a corner-case where what should be a steady, long, sequential big-block file read is actually a mixed smallish blocksize schizophrenic chopfest. The devs have no interest in fixing this because reasons.
After examining a Procmon capture I’m fairly confident if the filesystem’s read-ahead could be wildly extended to something like 13-14MB it would bridge most of the gaps, the read would become mostly sequential in nature, and these file loads would be dramatically faster. By dramatically I mean a 60-70% reduction from start to finish.
Does ZFS have such a knob? The OpenZFS defaults don’t appear to be adaptive enough to pick up on this.
Since this is a read, the ARC should take care of things (so having enough RAM). Plus, having the file(s) in question in a dataset with a large record size (1MB) should also help.
ARC works great until the blocks expire. I’m at 96GB RAM and can’t go any higher. L2ARC is helpful for the handful of blocks that find their way in. l2arc_headroom is zero, l2arc_write_max is cranked to low earth orbit, and l2arc_write_boost is cranked to the moon.
I did just discover that I’ve already set zfetch_max_distance to 13MB a while ago. I’ve just bumped it a little higher still…
Recordsize is 1MB. It was 256k earlier but it doesn’t seem to have made any difference here.
I don’t know what version of ZFS you’re running but here are a few more pointers (esp. since you’re already in L2ARC territory).
(the l2arc_mfuonly tunable is worth looking into for your use case)
Also, if the blocks are expiring, then there is “pressure” on the ARC in that something else is displacing those blocks which shouldn’t happen if the file is “hot”.
I guess there’s a lot more specific stuff that is relevant to your use case that you need to look into (on the other hand, too much “tuning” is also quite fragile - so beware).
Several. I think you were just getting tripped up because you were using the term “read-ahead” and the zfs devs use the term “prefetch” to describe the same basic concept.
Thanks for that. Neat article! I enjoy reading stuff from back in the days when Solaris mattered and wasn’t just a fancy bootloader for Oracle databases.
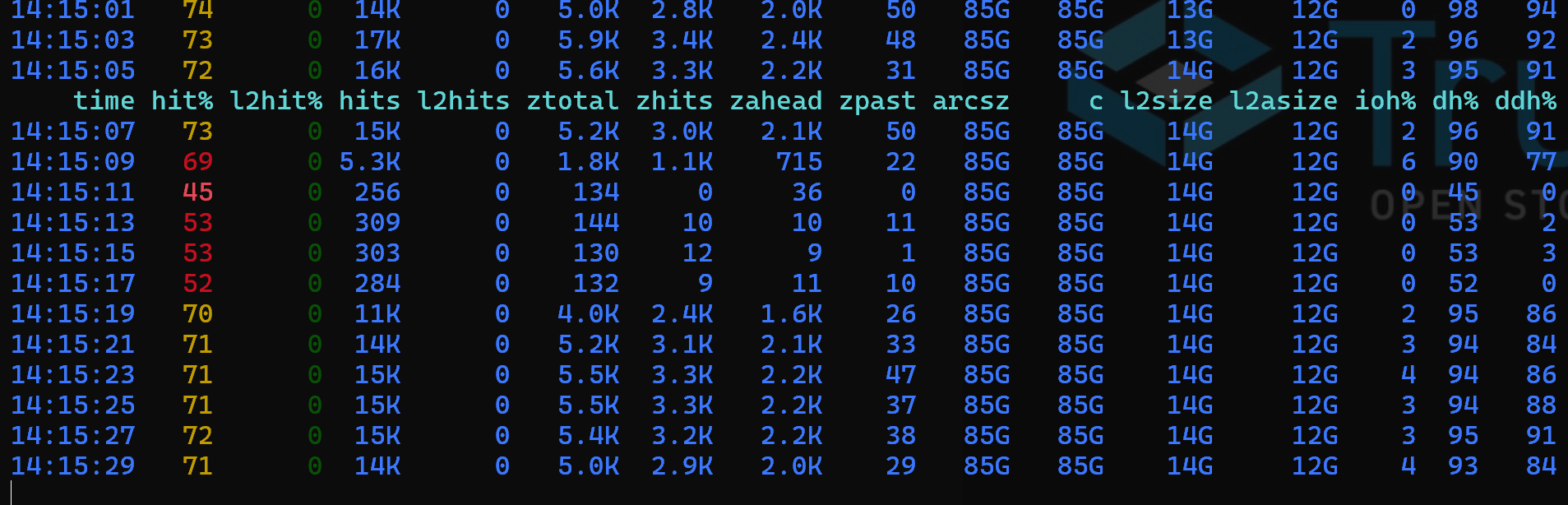
The prefetch is working a little better than I thought. I’ve discovered and added some zfetch columns to my arcstat: