You are correct, not encrypting a LOG vdev absolutely exposes every sync write you make, though only briefly.
Specials are a bit trickier. With default settings, all you expose with an unencrypted special is the metadata. Not encrypting your metadata may expose potentially sensitive information like file names, and could VERY theoretically make it possible for an INCREDIBLY advanced attacker in a really odd scenario to directly edit your metadata, giving them a toe hold possibly into manipulating your storage in a way that might grant them a pivot to some other layer.
That’s all VERY theoretical though; the only really significant risk there is exposing your metadata to reads. That’s assuming default settings, though. If you set special_small_blocks to 4K, for example, you’ll also expose all your dotfiles, since the DATA blocks of a file that small also hit the special in that case. You get the idea.
Samsung 990 Pro is a great example of a theoretically prosumer NVMe drive that is far less capable than it appears. Yes it supports massively high throughput for the simplest possible workloads (which you don’t have many or any of, in real life). But unlike the generations of SATA Samsung Pro models that came before it, the 990 “Pro” is all TLC–not MLC like the “slower” older SATA models–which means it REALLY falls off a cliff (eg write throughput at 10MiB/sec or less, with CRIPPLING associated latency) once you exhaust the small SLC cache allocated “at the top” of its physical media.
Meanwhile, the “slower” SATA Samsung Pros were ENTIRELY allocated MLC, and as a result could be relied on to keep providing 250+MiB/sec even for much more difficult workloads that might stay that busy for HOURS.
And even those older “Pros” get their asses handed to them–again, in tougher and more sustained workloads, NOT on simple single process sequential “tests”–by most proper enterprise or datacenter grade drives, like the Kingston DC600Ms I recommend so frequently.
If you’d like to examine the difference between “consumer fast” and “real workload fast” in more detail, check out this shootout I did for Ars a few years ago: https://arstechnica.com/gadgets/2020/12/high-end-sata-ssd-shootout-samsung-860-pro-vs-kingston-dc500m/
Spoiler for those who won’t click through:
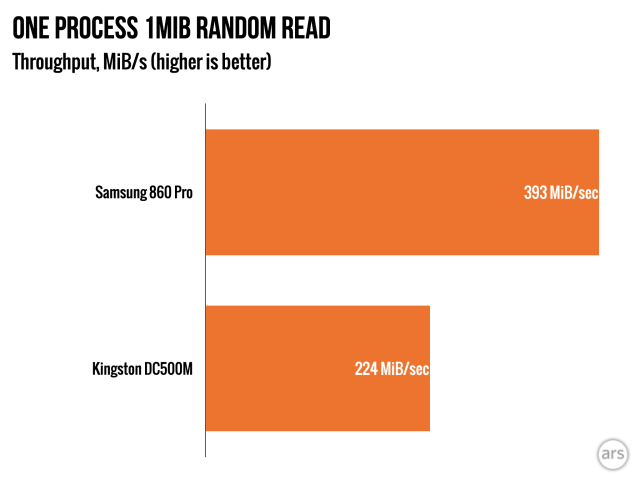
This is one of those unrealistically easy workloads I mentioned: and it’s still WAY more difficult than the ones the vendors themselves actually use, which are almost always pure consecutive writes, like you’d issue to a tape drive.
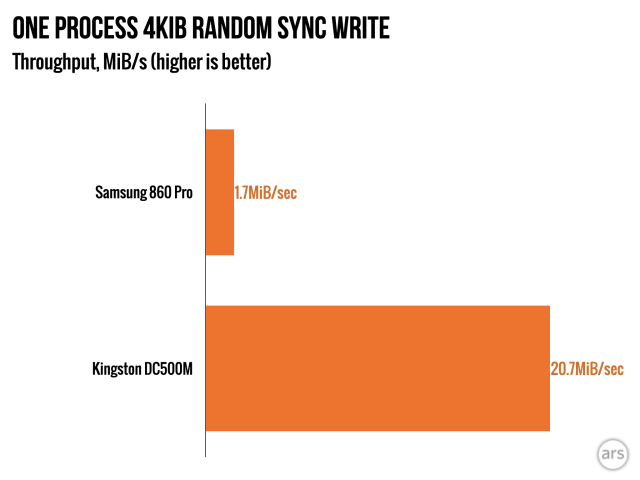
Oshit, sync writes have entered the picture! This is what you get from database engines, the vast majority of NFS exports, a lot of the stuff hypervisors do with storage, and occasional burst of “just because” from any given application or library that wants to make damn sure it knows all of its writes have already been committed before it does anything else.
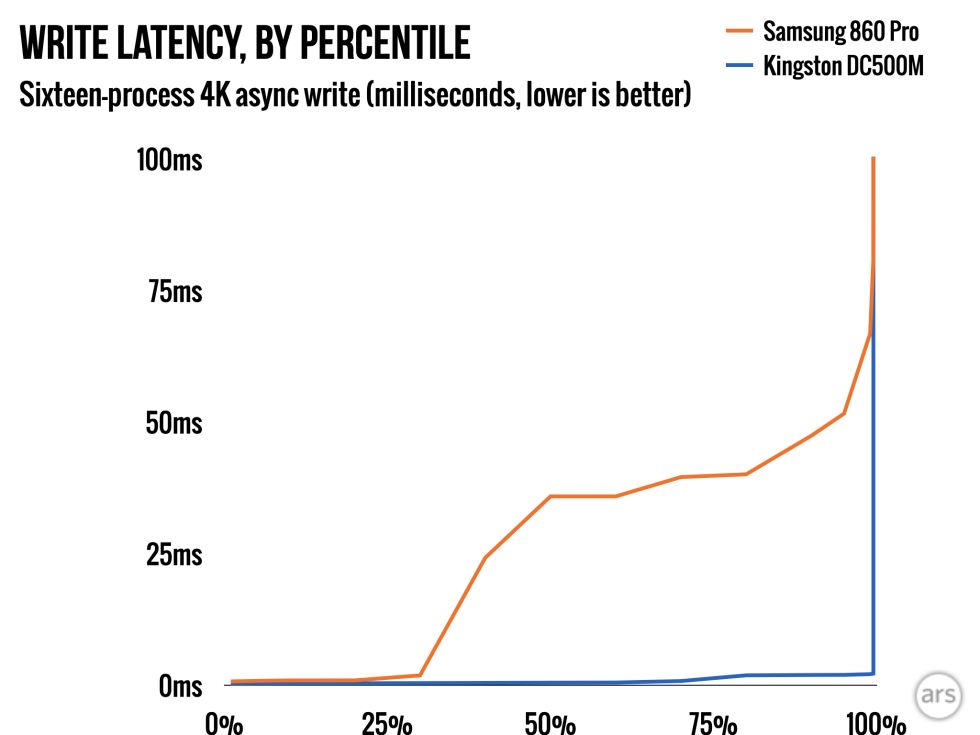
A surprising number of workloads demand not just “lots of operations fast”, but “lots of individual storage operations fast, and the actual thing you’re trying to doesn’t finish until ALL of those ops finish.” This is what we’re modeling here, and despite modeling it gently–with sixteen individual fully asynchronous processes, allowing parallelization–we can see how frequently we’re going to get a crappy result out of the Samsung.
If you need ten storage ops to complete before the application you’re using visibly does the thing you want it to, even with those ops in parallel, your application latency isn’t the median or the average latency, it’s the slowest return out of all ten parallel ops.
Now, look again at that latency chart. By the 95th percentile, the Samsung is taking 52ms to complete a write, while the Kingston is still finishing in a mere two milliseconds.
That’s bad enough when all you need is a single op: but if you need 10 storage ops to complete for each application op, that means a typical application op completes in <2ms for the Kingston, and WELL over 25ms for the Samsung. Brutal!