I’m adding larger drives to my pool, and as this is the first time I’m doing this, I decide to do some research before actually doing it.
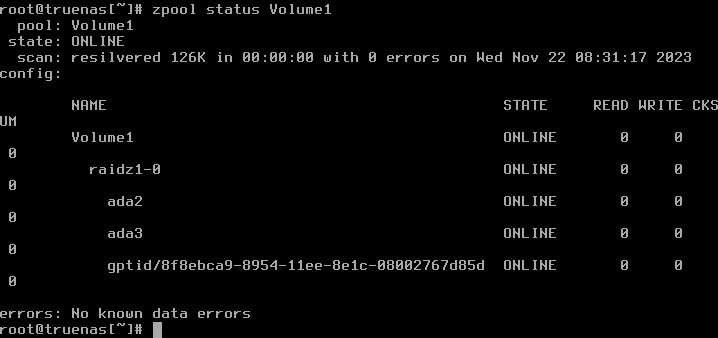
I believe I created this pool via the command line, instead of using the FreeNAS GUI, and it uses the geom ID and not the gptid.
pool: Volume1
state: ONLINE
scan: scrub repaired 0 in 0 days 06:50:04 with 0 errors on Tue Oct 31 06:50:19 2023
config:
NAME STATE READ WRITE CKSUM
Volume1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
ada5 ONLINE 0 0 0
I found different opinions on using a label vs the geom id. As far as identifying the drive, I usually label my drives during install, so I can easily check the SN if I need to replace it in the future.
I found a post saying that it’s better to use partitions because disk sizes are not perfect, but partitions are:
https://freebsd-questions.freebsd.narkive.com/XdKaE3zG/zfs-gptids-and-using-the-whole-disk
But I find it hard to believe that ZFS would not be able to handle a small difference on disk geometry. I always keep the same model of drives in a pool. The only factor I can think of would be replacing a faulty drive in a few years, were physical changes (upgrades, etc.) might have been added to that model and that difference might be higher.
On the other side, Oracle’s page recommends using the entire disk (but I’m assuming this is for specific for Solaris):
The recommended mode of operation is to use an entire disk, in which case the disk does not require special formatting
So my question is, as I’m replacing these drives, should I also change it to use a gpt partition instead?
I’m also wondering if I replace the drives using the FreeNAS GUI instead of the command line, if it will create the gptid (as per this post, “dont see /dev/disk/by-id”, FreeNAS uses gptid behind the scenes).
Thanks!