Hi folks–Klara Systems was kind enough to give me the chance to personally test and review the new fast dedup code which will be available in OpenZFS soon. (I used a provided pair of packages to install it onto FreeBSD 14.1, which does not include fast dedup by default.)
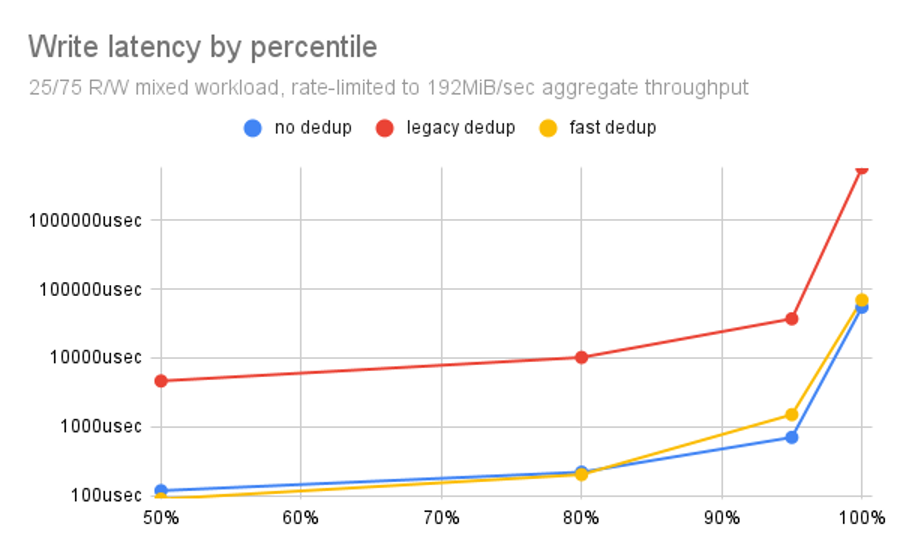
If you’ve ever been curious about OpenZFS dedup and wondered if / hoped it could work for you, the answer used to be “hell no” but it’s now been upgraded to “possibly.” In this article, I’ll walk you through the differences between using no dedup, legacy dedup, and fast dedup, along with plenty of charts to demonstrate the differences and explanations of why each matters.
And don’t get me wrong–most people still won’t find OpenZFS dedup to be a good fit. But the difference between legacy dedup and fast dedup is enormous.
I have had a limited amount of storage and through that felt that I had to do deduplication - as my pool was almost full and actually so full that with the limited deduplication, I had, it would have actually overfilled the pool. I know that stuffing the pool so full in itself is detrimental to pool performance.
Now that I have a little more free space, I am wondering if I should actually turn off deduplication. How does the affect the write latency? Is there still a penalty on writes as the pool has once been dedup-enabled?
Nope. As soon as you disable dedup, the write penalty disappears. I’ve heard that in some cases other issues might revolve around still being to keep the DDT fully in RAM, but on the one server I tried legacy dedup on in production for a couple years, when the write penalties got insane and I disabled dedup, everything was instantly fine, performance wise.