Here’s a snapshot of iostat during a scrub of my rustpool:

4x SATA drives in two mirror vdevs.
The numbers jump around a bit but I’m seeing rMB/s remain over 100 per drive for many minutes at a time. As depicted here the sum is 608MB/s and it’s exactly what I expect from this pool. To me it suggests no bottleneck on the storage side.
Here’s a long sequential read from this pool using a Windows host connected via 2x 10Gb iSCSI. At this point the file has been read multiple times and is fully cached in ARC:

To me this is close enough to the network’s “line rate” and it suggests no artificial bottleneck at the client or in the networking aspect.
Here is a “not cached in ARC yet” read of this same file @ 1M blocksize from the Windows client:
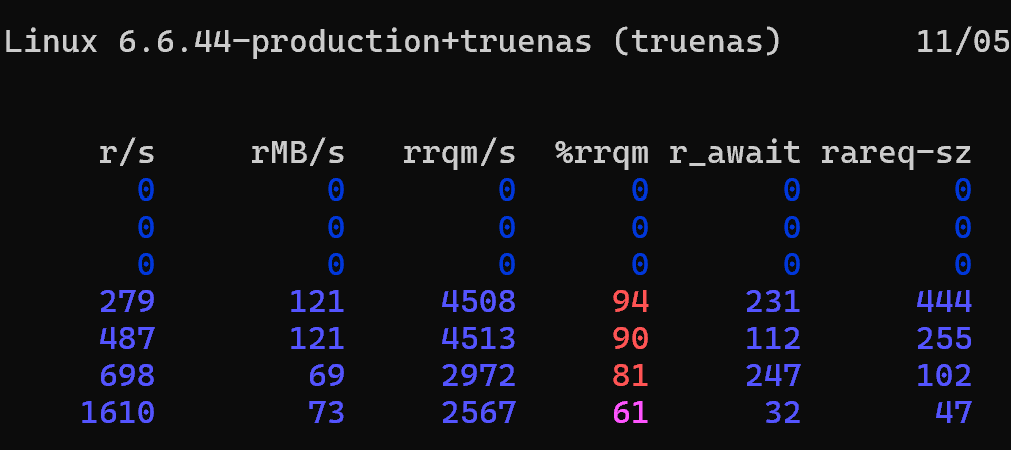
Each disk periodically goes to 100 %util – often in pairs – but they never remain there for more than 1-2 sample periods (2-4s in my case). The sum of rMB/s is 380MB/s – a far cry from the 608MB/s scrub throughput. Why?
Client throughput is even worse:

Less than half what the pool is capable of.
fio on the client returns numbers similar to DiskSPD.
fio on the ZFS host reading a test file at the root of this pool is somewhere in-between (about 400MB/s).
In the beginning I had recordsize=256k pool-wide and volblocksize=64k on this volume. I’ve since went to 1M records then re-created the zvol @ 128k (max volblocksize) – this helped a little. The client filesystem (NTFS) has been tried with both 64k and 1M clusters to no real effect.
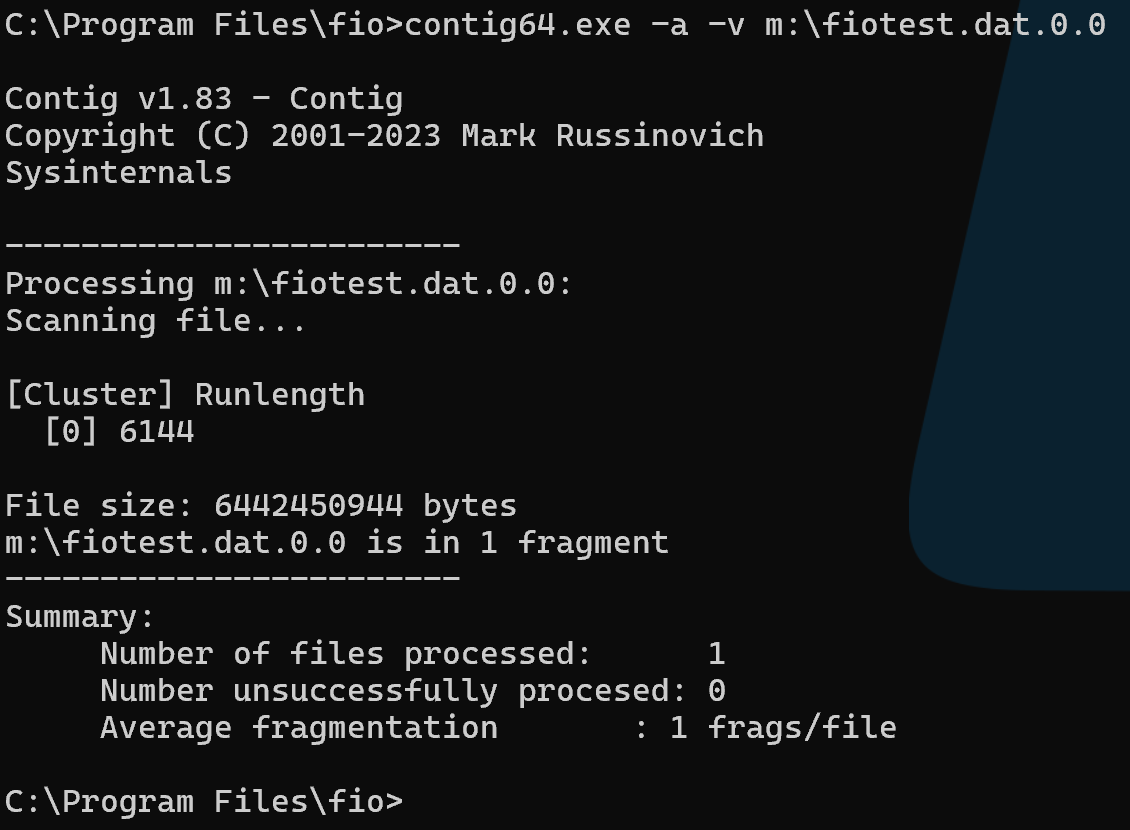
No fragmentation at the NTFS level:
In the iostat output I notice read IOPs (r/s) at the drive level often seem excessive for what should be a smaller number of big block reads.
My ZVOLs are sparse/thin and I strive to ensure UNMAP/TRIM is enabled and functional at every layer. So I’m wondering…

Is it reasonable to expect large block sequential reads to approach the sum of the drives max sustained throughput, and if so, how does one get there?
