My ZFS benchmarking from an iSCSI client has been narrowly focused:
- Large block sequential from testfiles just placed into ARC a few seconds earlier
- Random 4k Q1T1 (extremely latency dependent) to/from ARC using a tiny testfile.
The max I can stuff through a PCIe x4 slot running at PCIe 3.0 speed is 3200MB/s. This is via multipathing across 2x 25Gb links:
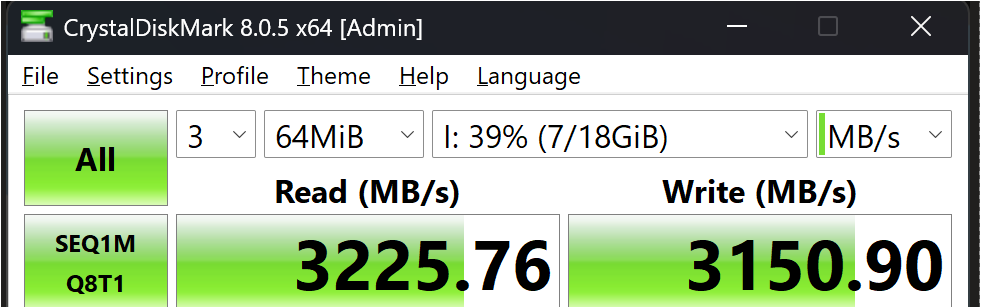
For 4k Q1T1 19-20k IOPs is typical… I can twiddle knobs and change drivers and see 22k but it hurts throughput too much:
For benching the rotating rust zpool I’ve run fio tests immediately after echo 3 > /proc/sys/vm/drop_caches to prevent cache hits from fouling the test. I also knock out L2ARC with zpool offline rustpool <CACHE_dev_guid>.
In all of the above I’ve never found measurable benefit from having more than 2 vCPUs assigned to my ZFS host. There are test scenarios where I’ve seen OpenZFS peg a third vCPU to 100% but the numbers were no better.
Well, I’ve finally found a reason to throw more vCPUs at ZFS.
From my client:
fio --filename=\\.\PhysicalDrive7 --name=test --readonly --norandom --rw=read --bs=1M --threads=1 --iodepth=32 --invalidate=1 --direct=0
This generates a continuous sequential big block read against an iSCSI volume that I don’t normally test. The back-end is a sparse file that replaced a zvol.
recordsize is 32k.
- 2x vCPU - 435 IOPs initial read - 1460 IOPs from ARC - 75ms 99th %ile
- 3x vCPU - 447 IOPs initial read - 1836 IOPs from ARC - 52ms 99th %ile
- 4x vCPU - 470 IOPs initial read - 2080 IOPs from ARC - 41ms 99th %ile
- 5x vCPU - 474 IOPs initial read - 2260 IOPs from ARC - 33ms 99th %ile
- 6x vCPU - 480 IOPs initial read - 2408 IOPs from ARC - 28ms 99th %ile
The above involved three runs for each vCPU count:
- “Initial read” has the client’s
fioread the entire volume from rotating rust right after a server reboot. This also populates the ZFS ARC which is large enough to hold the entire volume (about 30GB). - “IOPs from ARC” is the average of two additional runs. 100% of this is served from ARC as verified by watching
arcstatandiostatin real-time. - 99th percentile latency as reported by
fioat the end of the two ARC-cached runs (averaged together).
The host has only six physical hyperthreaded cores. Assigning more than this to a single VM is bad juju and contraindicated by Intergalactic Hypervisor Law. But I did it anyway.
For science:
- 7x vCPU - 478 IOPs initial read - 2453 IOPs from ARC - 25ms 99th %ile
Observations/comments:
- This is my first time running benchmarks in this manner. I have a long txg timeout and I’ve boosted
zfs_dirty_data_maxpretty high. So my past benchmarks were basically just reading back a few tens of MBs of whatever was sitting in the current open txg. Here I was reading an entire dataset from ARC well after it’d been committed to disk. - I’m wondering if one aspect of the ongoing zvol performance problem is an inability to parallelize correctly. If so it would explain why > 2 vCPUs was never beneficial. I need to redeploy some zvols and repeat this exercise. For science.
- I want to repeat this with a script on the client that copies all of the volume’s files to NUL instead of using fio against the underlying iSCSI volume. More of a real world test.
- My experimentation with server-side adapter offloads and packet coalescence and such hasn’t yielded much. Now that ZFS is leveraging the CPUs better I want to revisit some of this.
I don’t often read conversations about ZFS and core counts. What are you guys hearing?