So I’ve been a lurker for a while and really been benefiting from the great discussions both here and on reddit before that. Now I’ve come upon a situation I really don’t understand tho.
Background: I’ve got an Ubuntu server with 6 mechanical drives in ZFS pools. RAM total is 64 GB and I can’t easily add more. In general everything is peachy and I really like all the functionality available to me with ZFS.
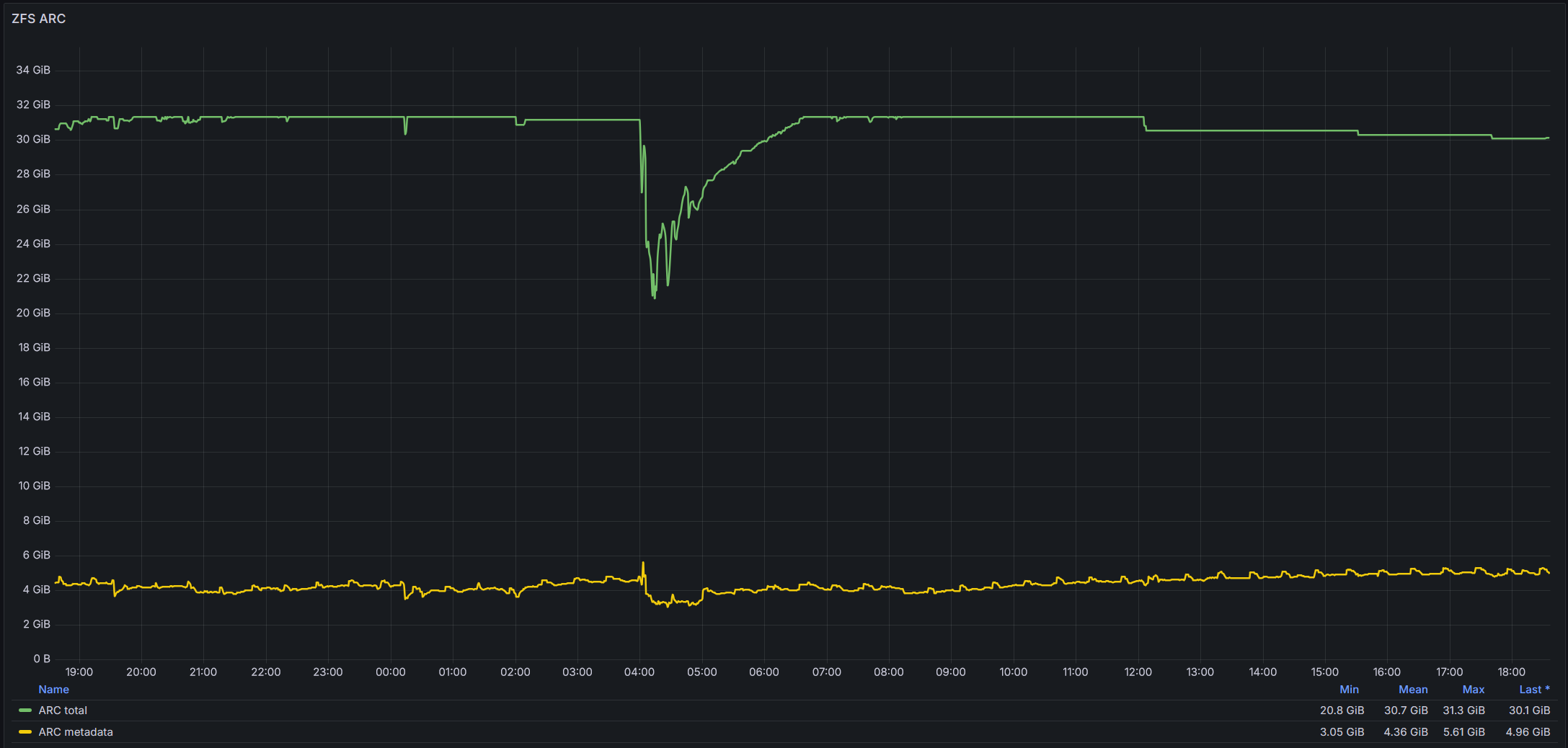
For various reasons I’d really like keeping all metadata in ARC. Running ls -lR > /dev/null at the pool root seems to work fine to populate the ARC with all metadata. First time running the command, it can take over 5 minutes to complete. Second time is 5 seconds (literally).
After running this on my pools I can see that my ARC metadata size is ~5.5 GiB. I’ve set my zfs_arc_meta_min to 6 GiB - this means that ARC metadata shouldn’t be evicted if it would take it under 6 GiB right? So the metadata should be “safe”?
But it isn’t. Even tho the ARC metadata size never exceeds zfs_arc_meta_min metadata is evicted from ARC. If I come back a day later and run ls -lR > /dev/null it takes in excess of 5 minutes again.
This is a graph of total ARC size and ARC meta size during 24 hours, all days follow the same pattern:
A backup using rClone and some other resource heavy tasks run every night, so I’m not surprised that the total ARC size is reduced as the system likely want more RAM for other tasks.
This is likely a good fit for a small CACHE vdev (aka L2ARC) and zfs set secondarycache=metadata nameofpool. Assuming you’re on a fairly recent version of OpenZFS, you’ll have L2ARC persistency across reboots, meaning that your metadata is not only going to fill in the CACHE vdev and be very, very difficult to displace from it, it will still be there after reboots without needing to refill.
If you have any particularly hot datasets you DO want to have actual data potentially show up in the CACHE vdev, you can manually set those back to the standard settings without changing the inherited defaults you set on the pool’s root dataset for other datasets: zfs set secondarycache=all poolname/datasetname.
If you’re feeling extra froggy, you can do this directly in ARC, without needing to add a CACHE vdev at all: the setting in that case is primarycache not secondarycache, and otherwise it works the same way. But of course, if you do that, you won’t get any data cached at all. That might very well be acceptable on a server used to stream viewable Linux ISOs; it would suck very much on a server running databases or what have you.
Although, again: you can carve out exceptions if you need to. This is a per-dataset setting, not a per-pool setting.
Thanks for the suggestion about metadata in L2ARC, I hadn’t really thought about that. I’m on ZFS 2.1.5 (Ubuntu 22.04) so I have persistency across reboots if I were to use it.
I have a surplus SATA SSD I could use, but am I correct in assuming that a NVME drive would be a lot better for L2ARC? I could use a partition of a NVME drive right?
As for setting primarycache to metadata, I hadn’t really thought about that either. There are some datasets where that might make sense (basically only Linux ISOs). I’ve learned something new today, thanks.
Any generic but decent consumer grade SSD should provide a very noticeable improvement, if you’re seeing issues that resolve with a hot metadata cache.
I STRONGLY recommend against doing that. The whole point of a CACHE or LOG vdev is improving latency. If you use a partition on a drive doing other things, you never know what that latency is going to look like, and you can easily make things WORSE if something else is happening on the other partition while you need access to the CACHE or LOG.
I recommend heavily against trying to make a LOG and CACHE vdev out of two partitions on the same drive, for the same reason. Big mistake, and a very very common one.
Thanks a lot for your comments, and also for the numerous articles and guides written by you I’ve found around the web. As an amateur home lab user trying to learn ZFS it has meant a lot.
If you did this with an SSD on a pool with only spinning rust, it would likely still make the pool faster, right? Even though latency would be inconsistent, it seems like an SSD would still have lower latency, even while serving both purposes, than spinning rust disks? Just curious if there’s any case where this might make sense.
If your LOG and CACHE are so lightly loaded that you don’t get inconsistent latency out of dumping both on the same device, generally speaking you didn’t need one or both of them in the first place.
I’ll gladly take some >1ms CACHE and LOG latencies here and there to keep I/O away from my spinners. I have just such a config (both on one drive) and now I want to assemble a fio job to hammer the drive and see what happens. Need to ponder this one a bit…