Thanks for taking the time to explain what’s going on–and for also reliving potentially unpleasant memories of your past interactions with the Proxmox devs … and Twitter people. (Aside: It’s amazing how much less useful The Former Twitter is for finding information now that I have to sign in to see most of it.)
Aside: I’ve started to put more effort into getting data I care about out of the virtual disk images I’m using. I started out experimenting, and then suddenly I was actually using the VMs to do things, and so there was suddenly production data in there. Oops. Real life keeps intervening, but my first priority is to finally, actually get my database storage onto an actual dataset in TrueNAS.
I really want to move them to datasets on TrueNAS so I can manage snapshots and everything else there–and because it’s so much easier to deal with recordsize without surprises than volblocksize.
So, my end goal is to have VMs with relatively small zVol-based boot disks, that use NFS and iSCSI and SMB to pull data from an actual properly configured ZFS-based storage server.
I’m going to have to read your messages and the twitter thread again a few more times to fully get my head around it, but I think it’s possible that someone at Proxmox quietly decided you were right and didn’t want to admit it out loud.
Maybe that contributed to them moving to 16k for the default volblocksize sometime late in PVE 7 or early in PVE 8. There wasn’t really an explanation of why except that it would improve performance. Quite a few forum users were pleased at the change, though the consensus seemed to be that it was a better default, but not a good one.
The docs at Proxmox VE Administration Guide have this to say about image formats:
Image Format
On each controller you attach a number of emulated hard disks, which are backed by a file or a block device residing in the configured storage. The choice of a storage type will determine the format of the hard disk image. Storages which present block devices (LVM, ZFS, Ceph) will require the raw disk image format, whereas files based storages (Ext4, NFS, CIFS, GlusterFS) will let you to choose either the raw disk image format or the QEMU image format.
- the QEMU image format is a copy on write format which allows snapshots, and thin provisioning of the disk image.
- the raw disk image is a bit-to-bit image of a hard disk, similar to what you would get when executing the dd command on a block device in Linux. This format does not support thin provisioning or snapshots by itself, requiring cooperation from the storage layer for these tasks. It may, however, be up to 10% faster than the QEMU image format. [35]
- the VMware image format only makes sense if you intend to import/export the disk image to other hypervisors.
My VM storage is a ZFS pool, so the only option I’m allowed to pick is raw. (If I were doing storage on NFS, I’d be stuck with qcow2, I think.)
I’ve always understood that a raw “disk image” means this is a zVol, so I’ve focused on setting volbocksize to 64k. Before I read your messages above, I didn’t even realize that storing VM raw files directly on ZFS datasets was a possibility. I don’t think I’ve ever seen official documentation about that.
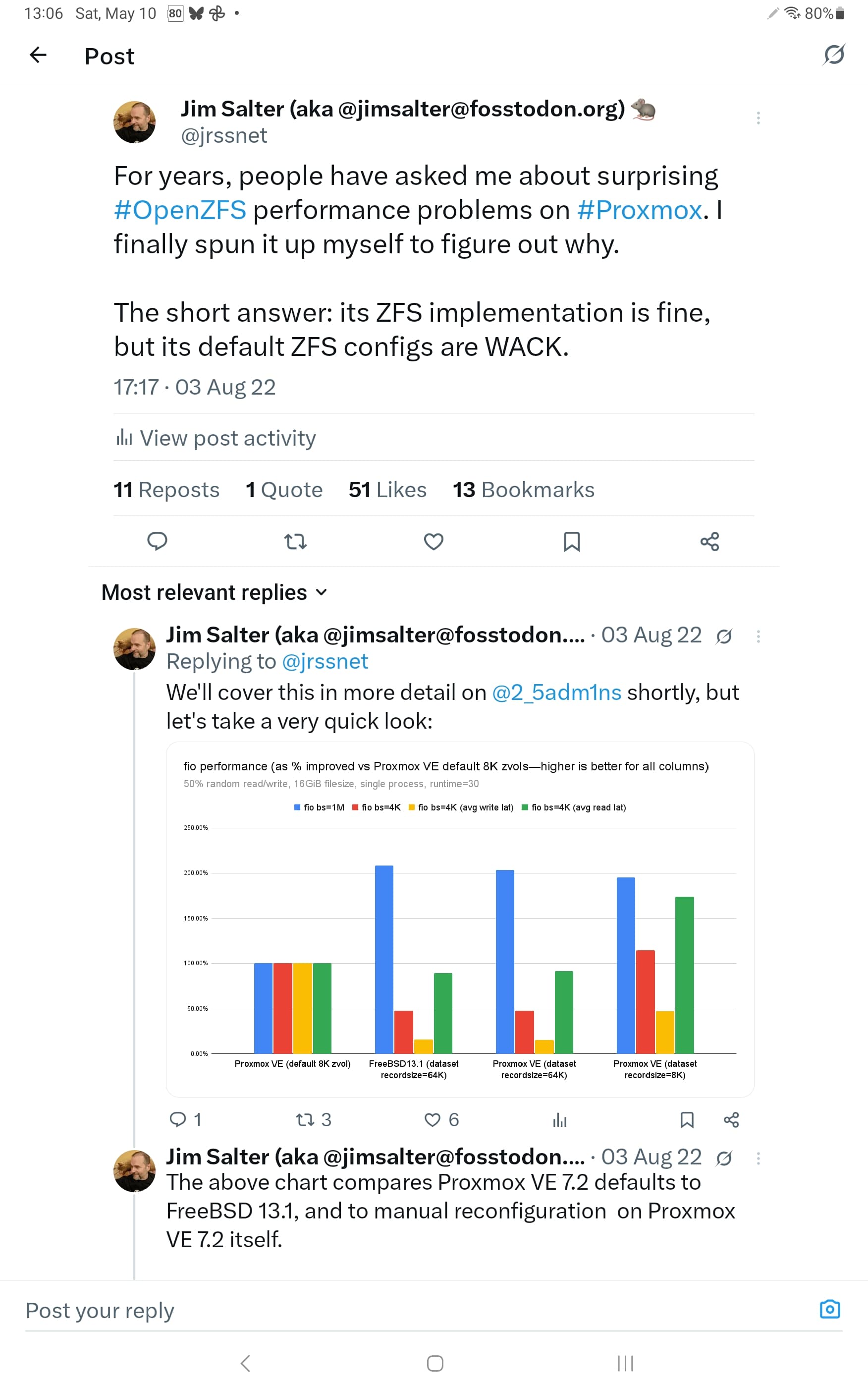
I discovered that it was using ZVOLs with VBS=8K, went A-HA, created a sparse file in a dataset with recordsize=64K on the same pool, ran the benchmarks and got the results I would normally expect.
I think that’s what I’m doing now? The recordsize on my pools is still the default 128k, because I didn’t know how to even guess to change it, or if it was worth it.
I added a dataset to my rpool called vmDisks64k and imported it into Proxmox as a ZFS storage “pool” (yes, this is weird; Proxmox exposes the dataset as if it were a pool in the PVE interface and lets me set a default volblocksize for any virtual disk that gets stored there). I set the default volblocksize to 64k for the pool and tried to forget about the whole thing, as I’d spent weeks trying to understand how it all fit together and flailing because Proxmox’s defaults and terminology are so strange.
All my VM virtual disks look like this when I poke at them with ZFS commands:
root@andromeda2:~# zfs get volblocksize | grep -i '64k'
rpool/data/vmStore64k/vm-99001-disk-2 volblocksize 64K -
Even though some of your results in your test showed better results with different/smaller sizes, is 64k still the sanest/least bad volblocksize to use for generic Linux/Windows/BSD VMs? I think it is, but I still need to re-read your messages a half-dozen times or so. 
I’m putting aside for the moment the issue of how the VMs treat the virtual disks by default in Linux guests. They’re recognized as SSDs with 512 byte sector-size, and I always end up going with ext4 because it’s simple and I have no reason not to. I have no idea if it would even be worth it to try to alter the recognized sector-size inside the VM, or possible, but I feel like that’s a level of diminishing returns optimization for home/SOHO server use, in any case. I hope.
I honestly got so exhausted trying to understand volblocksize for zVols/virtual disks and what counted as a good-enough default setting that I never got around to trying to optimize recordsize for LXCs, or even figuring out if I should bother. All my LXCs are stored in datasets using recordsize = 128k.