I am looking for some feedback to ensure my replication, backup and recovery procedure makes sense.
My virtual machines are important but can be quickly rebuilt.
My data served by Samba is critical and cannot be replaced (i.e. family photos)
I have adequate snapshots for my virtual machines (7 days of hourly)
I have adequate snapshots for Samba, 365 daily locally and 1095 daily remote
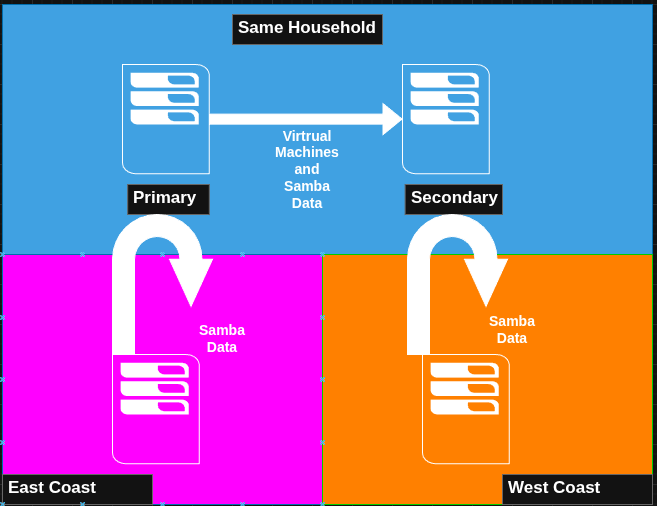
I have 4 servers in total.
Primary: hosts virtual machines in one pool and Samba data in a second pool
Secondary: acts as a hot spare, receives (push) replication of my virtual machines in one pool and samba data in second pool
remote1 on the west coast: a remote host to receive (pull) snaphosts from primary of my Samba data to a single pool
remote2 on the east coast: a remote host to receive (pull) snaphosts from secondary of my Samba data to a single pool
My thinking here is that;
If Primary has a hardware failure I can bring up my VM’s on the Secondary and start the samba service to serve my data. The VM’s will continue to operate using their same IP’s so no interruption there and minimal services such as scanning will require a manual IP change since the samba share is on a new IP (of the secondary host). I reconfigure sanoid on the Secondary to the snapshot schedule that was on Primary
remote1 will be unable to pull snapshots since primary is down, its replication state will begin to age
remote 2 will continue to replicate from secondary and will have an up to date replication status
Secondary will also be up to date since its now acting as the primary
When the primary comes back online I need to make sure to ensure that snaphots and replication are disabled
I then disable snaphots in the secondary and replicate the state back to the primary
I then reestate the snaphosts and replication on primary to ensure the secondary is kept up to date
remote1 will then be able to pull snaphots from primary to catch up to the current state
remote2 will continue pulling from secondary and maintain its current state
I am hoping this strategy balances risk of data loss noting I am operating in a degraded state while the primary is down with risk of misconfiguration due to stresses of recovering from an failure.
This is an extremely strong strategy as long as you’re actively monitoring and responding to problems.
I’m stressing that because I see so many people invest in unnecessary extra redundancy thinking it will be a substitute for active management–for example, going with RAIDz3 on systems that really don’t need it, but then never noticing drive failures because they assume the extra redundancy bought them all they need.
But if you set up active monitoring here, and pay attention to the monitoring, you’ll be in pretty good shape.
The only extra thoughts here: pull replication, not push–because your primary is the most likely machine to be compromised, and you don’t want to give an attacker control of your backups. So neither your secondary nor the DR box that replicates from the primary should trust the primary: you should not be able to SSH into them using any credentials that work on the primary, and ideally, you shouldn’t be able to SSH from the primary to any of the other three boxes. (Not being willing to accept incoming ssh from the primary AT ALL is a little stronger than I typically advise in a home setting, but you seem like you really want to build Fort Knox here, and this is an essential part of it, if you’re REALLY trying to go the distance.)
Similarly, the DR box that takes replication from the secondary shouldn’t be willing to accept ssh connections from either secondary OR primary.
Final note: dataset destruction won’t replicate when you’re pulling from the source, but dataset rollbacks absolutely will propagate, and cannot be recovered from if they do. You might want to consider delayed replication on at least one of your DR boxes, to buy you a little extra time if that happens.
That’s not just a hypothetical; it’s happened to me in real life. (Wasn’t a deliberate attacker, it was just a WEAPONS grade dumb fuckup from an employee at the client org, but that’s not the point.) If I had been replicating to the off-site DR there hourly–which is how frequently I replicate to the onsite hotspare–the damage would have been permanent.
I have definitely been guilty of throwing extra redundancy at a problem in place of monitoring.
I agree with your view on not trusting the primary, I have reconfigured the setup as suggested.
Monitoring is now in place and a spare HDD on site.
I actually hadn’t thought through the rollback risk. Out of interest, rather than delaying replication from the source, why not replicate the dataset again locally on the offsite with an offset (i.e. 2 copies on the offsite)?
My thinking here is that your get that offsite copy ASAP and there is minimal capacity overhead in extra snapshots until data is deleted.
I have never had to worry about rollbacks . I am trying to wrap destructive commands in a well tested scripts to prevent fat fingering. Alternatively I take a hit on speed and develop a recovery process using clones so I am always rolling forward rather than back - at least until I am comfortable I wont make a silly mistake in the heat of the moment.
Delayed replication is delayed replication. Split it up however you prefer.
I try to avoid replication chains, personally. I typically prefer to replicate both hotspare and off-site DR directly from the primary. Don’t want any unnecessary SPOFs, and in my experience that’s exactly what a dependency on an intermediate backup (eg if my DR replicated from the hotspare instead of directly from production) winds up being.
I don’t want to fail to get one component of my backup stack because a different component broke. Sort of defeats much of the purpose of the redundant backups in the first place, y’know?