The core issue is the hw-backups not being synced correctly and im not sure how to fix it. there are 3 devices that independently snapshot the dataset. my laptop, my main server, and this backup NAS. the backup NAS does not have sanoid installed to it, my main server and my laptop does
i have a feeling this is mainly because I don’t understand the sanoid options well enough to resolve this on my own ![]()
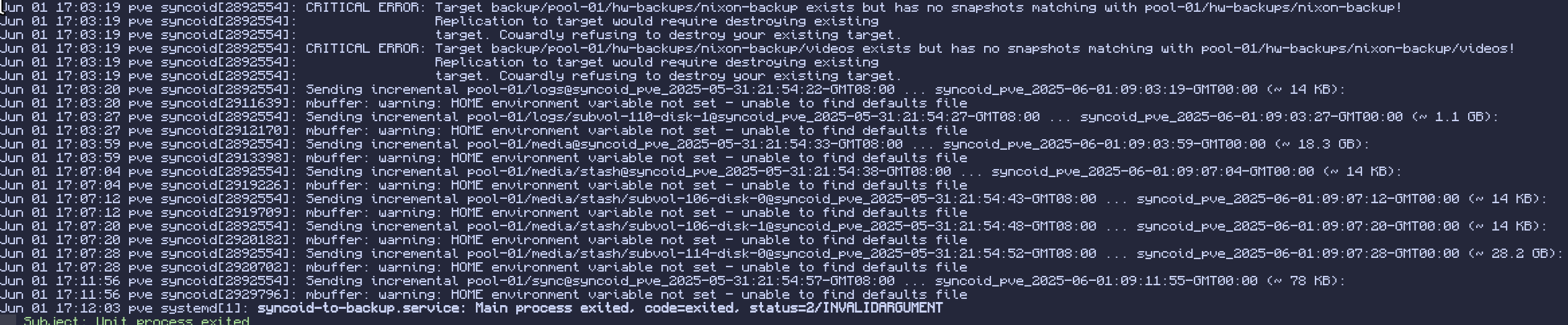
here’s the error that pops up on proxmox
# main server (pve/debian)
[pool-01/hw-backups]
# pick one or more templates - they're defined (and editable) below. Comma separated, processed in order.
# in this example, template_demo's daily value overrides template_production's daily value.
use_template = backup
recursive = yes
...
[template_backup]
autoprune = yes
frequently = 0
hourly = 30
daily = 90
monthly = 12
yearly = 0
### don't take new snapshots - snapshots on backup
### datasets are replicated in from source, not
### generated locally
autosnap = no
### monitor hourlies and dailies, but don't warn or
### crit until they're over 48h old, since replication
### is typically daily only
hourly_warn = 2880
hourly_crit = 3600
daily_warn = 48
daily_crit = 60
syncoid command from proxmox to backup NAS
/usr/sbin/syncoid --recursive --delete-target-snapshots pool-01 truenas_admin@192.168.100.146:backup/pool-01
syncoid command from laptop to main server/proxmox
commands."backup_persist" = {
source = "rpool/persist";
target = "hyperboly@192.168.100.130:pool-01/hw-backups/nixon-backup";
extraArgs = [ "--sshport=2200"
"--no-privilege-elevation"
"--delete-target-snapshots"
"--no-stream"
];
recursive = true;
};
# laptop config in nix
services.zfs.trim.enable = true;
services.sanoid = {
enable = true;
datasets = {
"rpool/persist" = { # using nixOS impermanence so this is the only dataset that needs to be synced
hourly = 50;
daily = 15;
weekly = 3;
monthly = 1;
};
"rpool/persist/videos" = {
hourly = 0;
daily = 1;
weekly = 3;
monthly = 1;
};
"rpool/persist/steam" = {
hourly = 0;
daily = 0;
weekly = 0;
monthly = 0;
};
};
};