Good morning. I recently migrated my server from Ubuntu to FreeBSD. I had a working Sanoid setup before. Since the migration, I’ve tried to send some datasets to both other pools on the same machine and the remote host (with no changes) that I was using previously. I getting into the situation in the screenshot. The transfer begins without any errors but at some point always hangs. I have confirmed with zpool iostat the relevant disks have little to no activity when this is happening. I have a minimally edited sanoid.conf that has worked for me since I started using sanoid. I’m kind of lost on what else to do to troubleshoot this and could use some help. I tried to post additional screen shots but the system won’t let me because I’m new. I can provide additional information as needed.
You can copy the text from your terminal and either select the code box/preformatted text box in the Discourse editing toolbar, or you can start a new line with three back ticks (```) to start creating a code box. Just make sure your final line also ends in three back ticks to close the box.
Doing that, you don’t have to worry about uploading screenshots. Besides, it’s much easier for other users to read.
In your screenshot, you see the command line it’s showing you that begins with ‘zfs send’? That’s the actual command syncoid constructs for you, and you can run the same thing from the command line yourself.
So, here’s the next thing you want to do for troubleshooting purposes: see where the ‘zfs send’ command then gets piped into ‘mbuffer’ and then ‘pv’? Change that pv command to pv > /dev/null and then try running the command.
What you’re finding out by doing that is whether it’s the zfs send process that’s hanging, or something after the zfs send process. So let’s give that a shot, and report back please.
OK, now we’re getting somewhere. This is a FreeBSD system, right?
I think pv is broken in pkgs on FreeBSD right now. Try pkg remove pv and running syncoid again; without pv available syncoid drops back to a more primitive built-in progress bar.
If your syncoid command completes fine with pv uninstalled, that confirms presence of the bug in pv, which you’ll need to take up with FreeBSD upstream. You should be able to install an older version or compile from source or something, but I’m not the last-mile support for that.
It is FreeBSD. But it wants to yank sanoid out as well.
root@prod0:~ # pkg remove pv
Checking integrity... done (0 conflicting)
Deinstallation has been requested for the following 2 packages (of 0 packages in the universe):
Installed packages to be REMOVED:
pv: 1.8.10
sanoid: 2.2.0
I took some action before I saw your latest message. I can go back and do as you recommended when what I did finishes. What I did was remove the pv package and consequently, sanoid. Then I went into the Makefile for the sandoid port, deleted the pv, and built and installed the port. It is a tad indelicate, but I’m watching it with zpool iostat and so far it is working. Does that do enough to confirm the issue?
Edit: I created a boot environment first. I can roll back if it really screws something up.
Since you got a deadlock again, let’s just pipe the zfs send straight to /dev/null, please. If that also locks up, there’s something wrong with your pool. If the zfs send piped to /dev/null completes fine, then we need to look further down the chain.
Well, we know that at a minimum, your system will eventually get through a zfs send. Unfortunately what we have no idea about is how long that takes, or whether there are long hangs in the middle.
You could maybe try it again, but this time time zfs send [arguments] > /dev/null ?
As long as you know how long the send actually is–which you can first get by appending the --dry-run argument to the zfs send command–you can compare that with the time elapsed to figure out the average speed, which will in turn tell you how long you really ought to wait before concluding that the original syncoid would never complete.
That’ll also give us some indication about what to expect in general, how practical it might be to try manually scp’ing the send stream over to the other machine to manually zfs receive it there (for troubleshooting purposes, not as a permanent solution), etc.
Here is, hopefully, what you asked for. It really seems to not like the snapshots from 7-28 for some reason.
root@prod0:~ # zfs send -nv files/cjr/Pictures@syncoid_backups_2024-07-28:00:00:10-GMT-05:00 > /dev/null
root@prod0:~ # zfs send -nv files/cjr/Pictures@syncoid_backups_2024-07-28:00:00:10-GMT-05:00 |zfs recv media/test/garbage
cannot receive: failed to read from stream
root@prod0:~ # time zfs send files/cjr/Pictures@syncoid_backups_2024-07-28:00:00:10-GMT-05:00 > /dev/null
586.80 real 0.00 user 16.44 sys
I cloned that snapshot and mounted it where I could look at the innards. I don’t see anything wrong, but I did not look all 20 years worth of pictures.
root@prod0:/mnt/broken # zfs send --dryrun -v files/cjr/Pictures@syncoid_backups_2024-07-28:00:00:10-GMT-05:00
full send of files/cjr/Pictures@syncoid_backups_2024-07-28:00:00:10-GMT-05:00 estimated size is 110G
total estimated size is 110G
Ok good, you got around 200MiB/sec. Perfectly healthy. Problem isn’t the send process. I still suspect it’s a bug in pv or mbuffer, but let’s keep isolating out “things that work by themselves” to be sure.
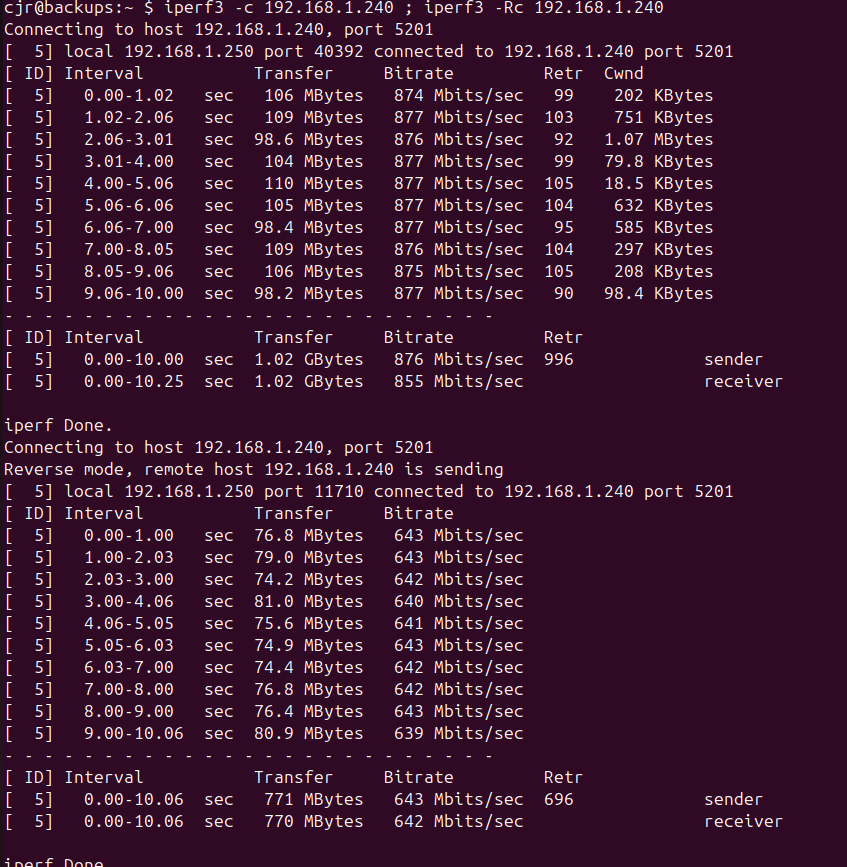
Can you run iperf3 on both sides to look for network issues? (You may need to pkg install it first.)
OK, you’ve clearly got one of the network interface chipsets that FreeBSD doesn’t have a decent driver for, from the looks of those iperf runs (the 877Mbps in one direction is decent if mediocre, but the pairing of it with 640Mbps runs in the other direction makes it clear this is one of the chipsets FreeBSD doesn’t like). But while that’s an issue, I’m not sure it’s the issue that you’re looking to solve.
Before asking you to buy a different network card, let’s make sure that you can send and receive successfully when the network is not in play:
That will both make sure that you actually can send and receive between these datasets successfully, and get you up-to-date with backups for the moment while we look at our next move.