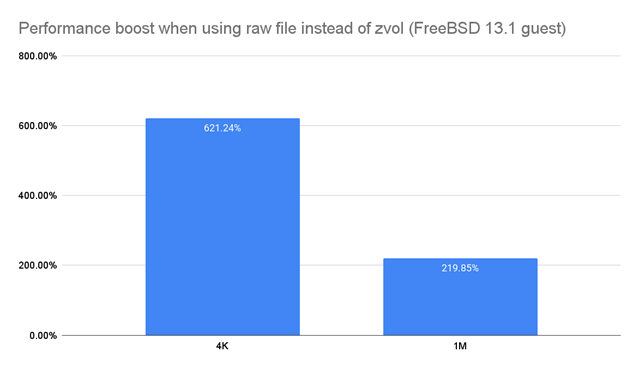
Long story short, I want to run a high IOPS PostgreSQL dependent database in a Docker container inside a KVM VM on a ZFS filesystem consisting of NVME SSDs. All this would run on Proxmox. What settings should I choose for high performance? I have been using ZFS for a while and know the basics, but this setup confuses me.
The setup: Proxmox(ZFS(KVM(Docker(PostgreSQL))))
Of course I should run benchmarks, but please give me your best guess. This is what I have so far:
ZFS Settings
- Mirror VDEVs
- Set ashift=12 (are SSDs better with ashift=13?)
- Set recordsize and volblocksize to 16k
- Set compress=lz4
- Set atime=off
VM Settings
- SCSI controller: VirtIO SCSI Single
- Enable iothread
- Enable Discard for VM and within VM
My questions:
-
Are my settings a reasonable choice for performance?
-
Would ashift=13 be better for modern SSDs? Please explain.
-
Is my 16k recordsize a good choice? I know PostgreSQL works best with 16k (please correct me if I am wrong), but what about VM image size? Will Docker affect my choice? This is the most uncertain thing in my setup for me. Please explain.
-
What would change if I don’t run a dedicated ZFS pool for my PostgreSQL database VM, but store the VM image directly on the Proxmox root pool (zroot)? Of course, the VM would have to share performance with other VMs. But what else?