Hey All,
I’m trying to understand ZVOLs a bit more and I haven’t found an answer that makes much sense in any of the openzfs or oracle docs I’ve come across. Do ZVOLs actually run on top of a zfs filesystem or are they just logical devices? I’ve generally avoided ZVOLs because I tried to avoid any potential performance impacts or complications from having nested filesystems. Thanks
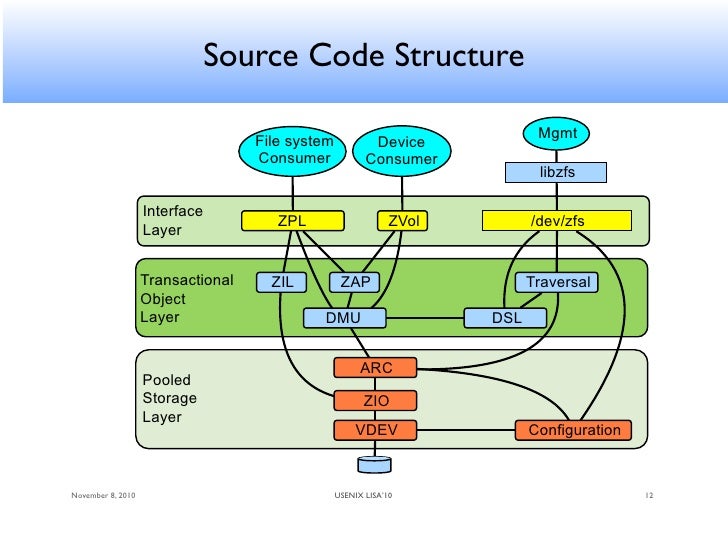
Both zvols and filesystems (ZPL - zfs posix layer) are datasets that sit above the DMU (data management unit) layer. Neither is layered on the other.
There are differences in the way the IO pipeline works that tends to give filesystems better performance. Or at least that was the case several years back. I’ve not kept up with zfs development to see if zvol performance has improved.
It’s been reported to be “performance fixed! just as fast as normal datasets now!” several times over the last fifteen years or so; so far I have disagreed strongly with that assessment each time somebody presented me with it and I then tested it.
Allan (Jude) recently told me that performance problems had been addressed in zvols… but it ain’t even the first time Allan has told me that, and at this point I will only believe it when I actually test and confirm it, and not before! 
So normal datasets are more performant than a zvol? I understand that the use case between zvols and normal datasets is very different but I’m a bit surprised to hear that.
When I talked about filesystems being layered, I could have added a better example. The diagram helps me somewhat in understanding how the two are connected and gives me some idea of the answer, but if any filesystem has overhead and if have a ZVOL that I format that to, ext4 or something, do I get the overhead over ext4 + the the overhead of zfs?
People misuse the term dataset. As defined in the code, filesystems, zvols, and snapshots are all datasets.
If you put ext4 or any other native Linux filesystem on top of a zvol, you will have the overhead of both. Since zfs uses the ARC for caching and ext4 uses the buffer cache, you may end up with the filesystem data and metadata being cached twice. Managing two caches has CPU overhead in addition to storing an extra worthless copy in RAM.
You get some of the overhead of ZFS in addition to all of the overhead of ext4.
Specifically, you get the overhead in the form of checksumming, compression (if any), encryption (if any), and so forth. The overhead you don’t get is the actual filesystem bits of ZFS–so, no inodes or other filesystem metadata, just the block management stuff.
You will also end up with double caching, if you don’t manually disable ZFS caching on the zvol… which would pretty much suck in a lot of circumstances, since ZFS’ cache is considerably smarter than the kernel page cache. ZFS won’t cache ext4’s inodes and other metadata as inodes and metadata, but it will cache their blocks just like it caches any other blocks… which the kernel page cache won’t know about, so it will also cache them there as metadata.
Ah, you guys are awesome, thank you for taking your time to answer that, it makes much more sense. So a ZVOL would make sense if I wanted a block device AND zfs features like checksumming/compression/encryption. Otherwise I might as well just create a partition on a disk or use LVM then, correct?
Yes, that’s exactly correct. 
Interesting thread. SCST iSCSI targets can be backed by either files or block devices on the host system. Might there be value in skipping the zvol aspect and using file-backed targets? I’ve never tried this but I’m very intrigued…
1 Like
I cannot promise that will solve your problem, but if your problem were my problem, I would very much be trying that and running tests to document whether it improved things and, if so, by how much.
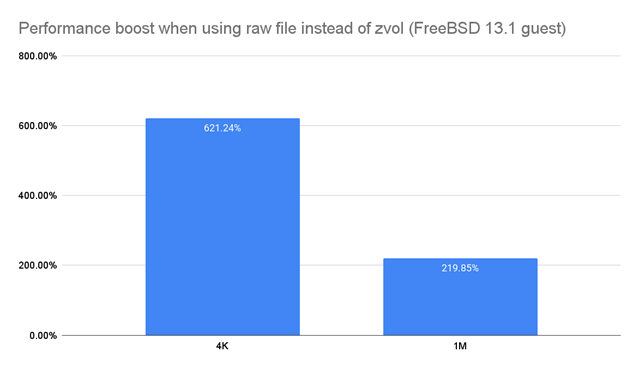
And I would expect to see some significant improvements when doing so. Here’s an example of the performance boost I saw when explicitly testing zvol vs raw file back-ends on the bhyve hypervisor under FreeBSD 13.1 last year:
This always shocks the hell out of people, but it’s a difference I’ve been observing for well over a decade. To be fair, it did shock me too, the first time I saw it… but like I said, that’s been well over a decade ago. At this point, I’m like “yeah zvols suck” and only bother to re-test it again before publishing something new where I know it’s going to reach a lot of people who will be surprised by that, and will really need to see it demonstrated.
1 Like
Every time I heard about ZVOLs, they seem like a solution desperately in search of a problem.
I can’t agree with that one, honestly. VMs are the obvious problem that ZVOLs should, in theory, be a perfect solution for.
The only problem is that they suck.
1 Like
Set up my 1.5TB NTFS-on-iSCSI volume file-backed instead of zvol-backed. Used truncate to create a sparse file. Only tested big block sequential (as it’s the primary use case for my SAN/NAS).
From the Windows client I’m seeing a 10-20% throughput bump. Most notable is rareq/sz in iostat remains largely pegged at 1024 whereas with the zvol it was bouncing around. This is essentially equal to the SMB fileshare I had with the extra benefit of actually useful client side caching.
Unfortunately this didn’t negate the need for zfs_vdev_async_read_max_active=1 along with a few other tunables for max read throughput. I was hoping to return tunables to defaults.
So I call it a win. In the bar chart above what type of I/O specifically was measured on BSD?
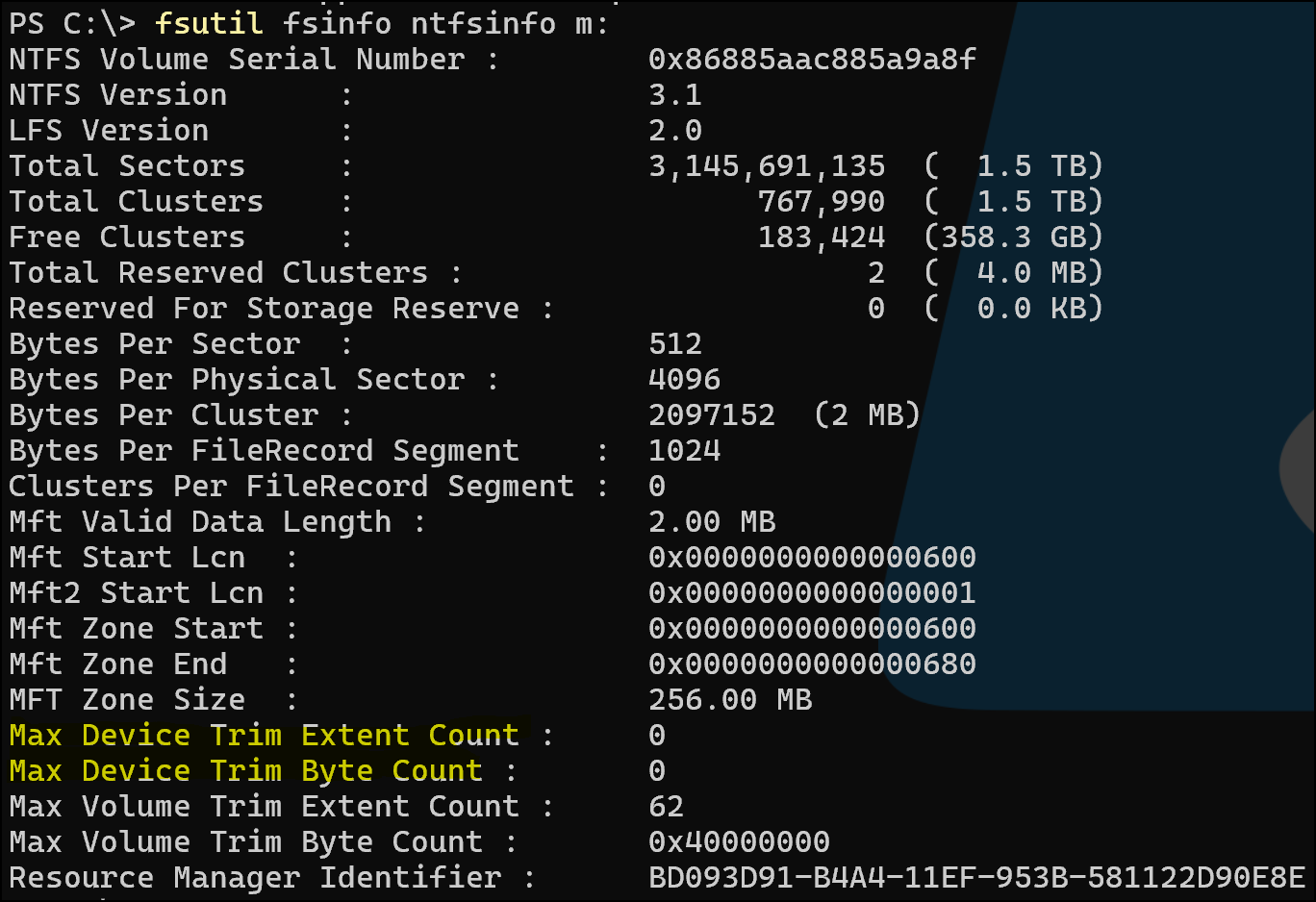
Edit: Windows can’t TRIM/UNMAP this volume. SCST is apparently responding “no can do” to whatever SCSI inquiry detects thin provisioning.
Edit2: Added thin_provisioned 1 to the relevant device within the HANDLER vdisk_fileio section of scst.conf. Still no TRIM:
Wondering if this is a zfs limitation or an SCST limitation…
Random writes at the blocksize shown on the chart.
So I have to ask… Just what do you gain from a zvol vs a raw file?
A zvol is a block device but a file can be mounted also as block, no? This is a Linux thing and not exclusive to zfs. Seems like a tie…
From a snapshot perspective a zvol is a dataset and can be snapshotted. One can also create a dataset containing nothing but said raw file. Another tie.
zvols can be sparse. Files can be sparse. Tie.
zvols are limited to 128k max blocksize. Does this imply the recordsize for said zvol is also 128k? Or can ZFS aggregate multiple blocks in a record? For a file I reckon the dataset’s recordsize can be as large as zfs can handle. Not sure about this one but it seems like a tie at best.
zvols mounted as block and presented as SCSI devices appear to handle TRIM/UNMAP exactly like they’re supposed to. I’m still working out how this is handled with files. In my case the SCST/OpenZFS stack does not accept UNMAPs from an initiator. I’m still researching this one. Hopefully I won’t need zero-punch hackery to get around this limitation.
Performance-wise, zvols seem like a headache. They’ve been a headache for me. File-backed volumes are a clear winner in my case. zvol CPU overhead is much higher and I can’t find a use-case where the overhead is justified.
What am I missing?
I don’t think you’re missing anything. I think you’re just one of the very few people (welcome to the club, dues are low but it’s not that prestigious) who have actually tested zvol performance instead of just blindly assuming it’s great.
1 Like